Unlocking the Power of Support Vector Machines: A Comprehensive Guide
Unlocking the Power of Support Vector Machines: A Comprehensive Guide
Support Vector Machines (SVMs) have revolutionized the field of Machine Learning (ML) by providing a powerful tool for classification, regression, and other tasks. By leveraging the principles of statistical learning theory, SVMs have been successful in various applications, including image classification, text classification, and bioinformatics. In this article, we will delve into the world of SVMs and explore their practical implementation through a step-by-step tutorial.
What are Support Vector Machines?
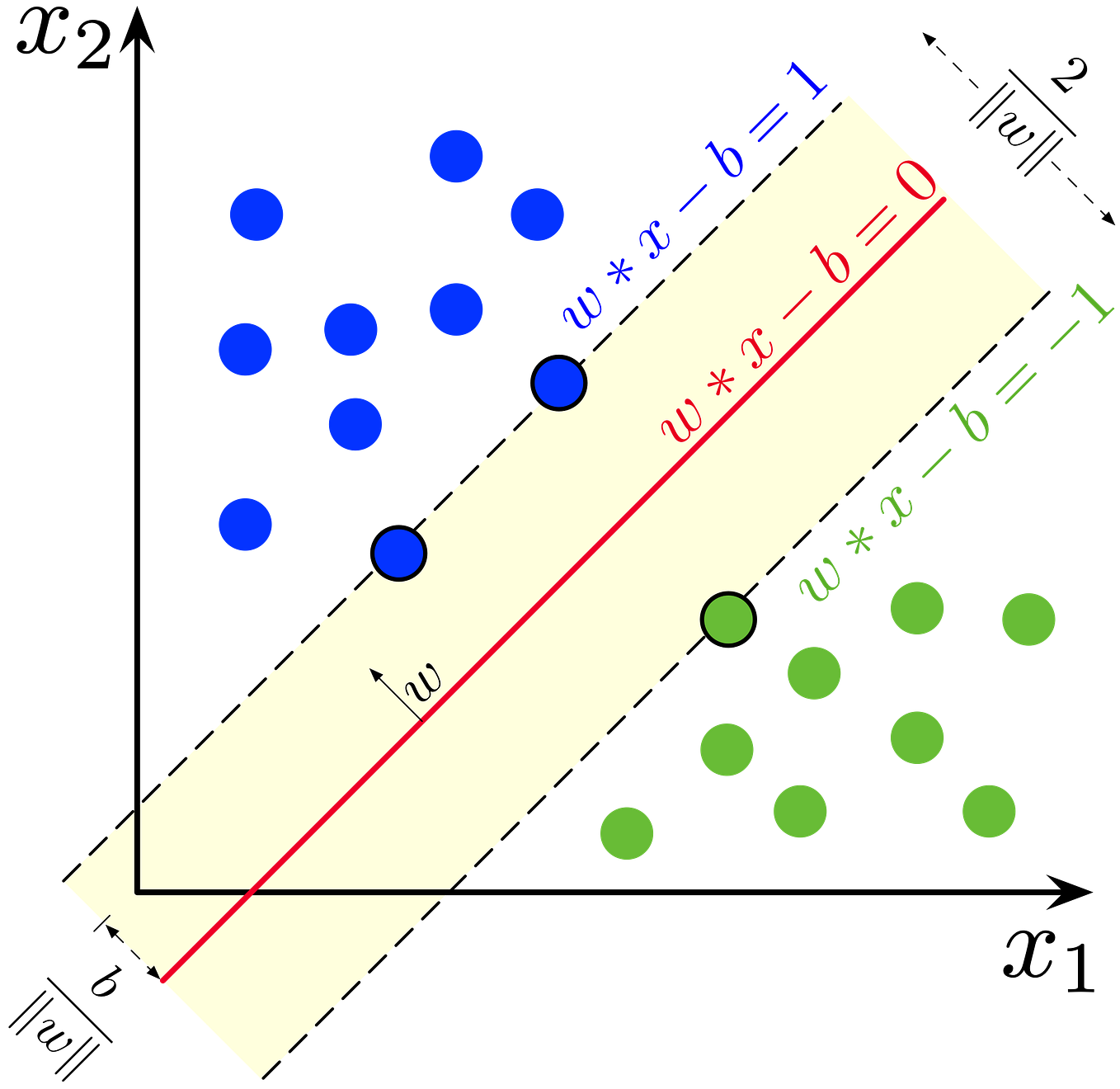
Support Vector Machines are a type of supervised learning algorithm that aims to find the optimal hyperplane that separates classes in a high-dimensional space. The term "support vector" refers to the set of data points that lie closest to the hyperplane, which are known as the support vectors. These points are crucial in determining the orientation of the hyperplane and, consequently, the predictions made by the SVM.
"SVMs are not just another classification algorithm," says Dr. Maria-Florina Balcan, a leading researcher in the field of ML. "They are based on a deep understanding of the fundamental limits of learning and provide a systematic approach to designing classifiers."
Key Components of SVMs
There are several key components that make up an SVM, including:
* **Kernel**: The kernel is a crucial component of SVMs, as it allows the algorithm to operate in high-dimensional spaces. The goal of the kernel is to map the input data to a higher-dimensional space where the classes can be more easily separated.
* **Hyperplane**: The hyperplane is the decision boundary that separates the classes in the feature space. The goal of the SVM is to find the optimal hyperplane that maximally separates the classes.
* **Support Vectors**: As mentioned earlier, support vectors are the data points that lie closest to the hyperplane. They play a critical role in determining the orientation of the hyperplane.
* **Margin**: The margin is the distance between the support vectors and the hyperplane. The goal of the SVM is to maximize the margin, which leads to a more robust and generalizable classifier.
Types of SVMs
There are several types of SVMs, including:
* **Linear SVM**: A linear SVM is the simplest form of SVM and is used when the classes are linearly separable.
* **Non-Linear SVM**: A non-linear SVM is used when the classes are not linearly separable. This type of SVM uses a kernel to map the input data to a higher-dimensional space.
* **One-Class SVM**: An one-class SVM is used to isolate a class from all other classes.
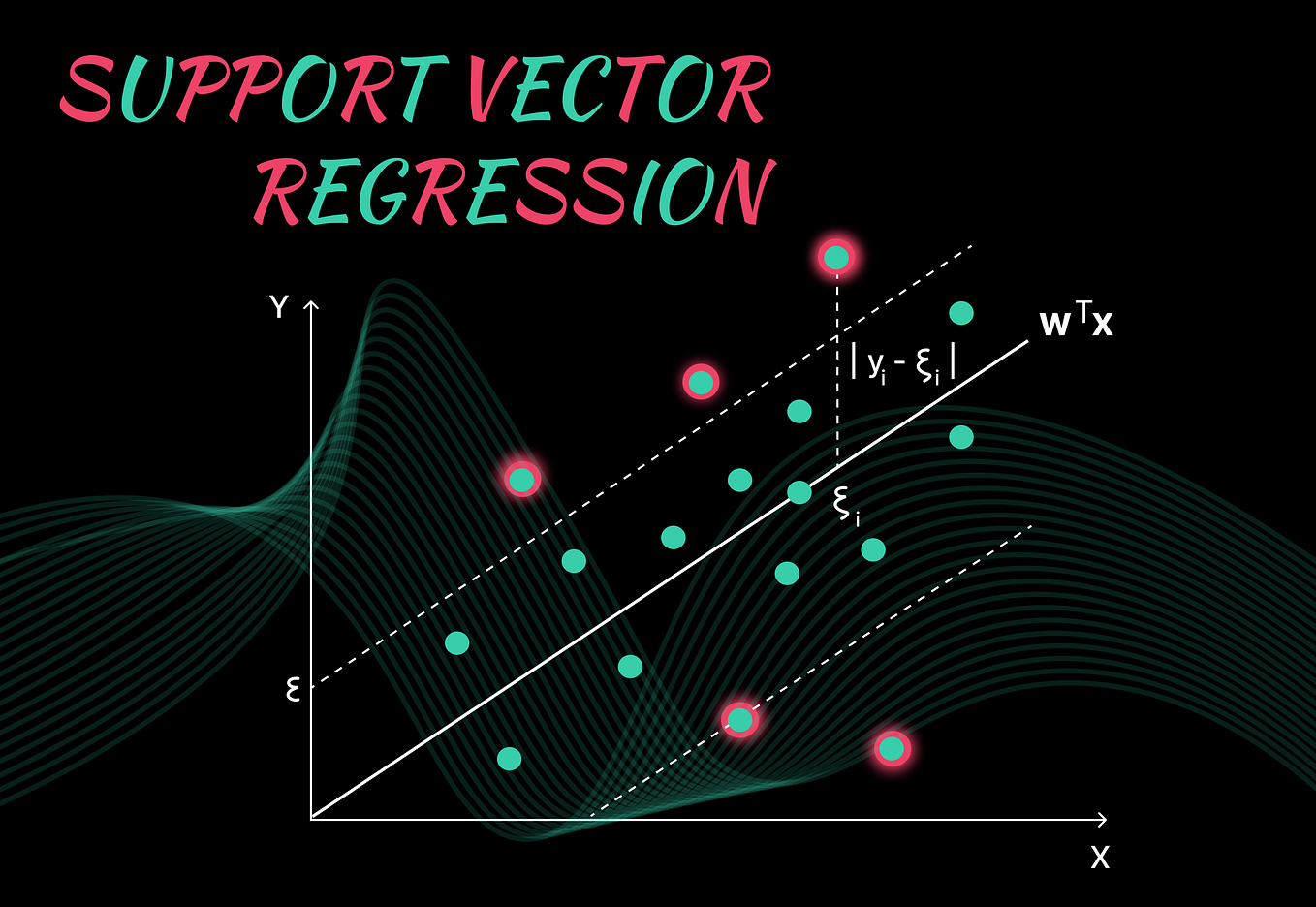
* **Regression SVM**: A regression SVM is a variant of the SVM algorithm used for regression tasks.
Step-by-Step Tutorial: Building an SVM Classifier
Let's walk through a practical example of building an SVM classifier using Python and the scikit-learn library.
**Dataset**: We will use the Iris dataset, which is a classic multiclass classification problem.
**Step 1: Data Preprocessing**

We start by loading the Iris dataset and performing necessary data preprocessing tasks, such as encoding categorical variables and scaling numeric variables using StandardScaler.
**Step 2: Splitting Data**
```python
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Split the data into feature matrix (X) and target vector (y)
X = iris.data
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, iris.target, test_size=0.2, random_state=42)
```
**Step 3: Training the SVM Classifier**
```python
from sklearn import svm
from sklearn.metrics import accuracy_score
# Initialize the SVM classifier with a radial basis function (RBF) kernel
svm_model = svm.SVC(kernel='rbf', C=1)
# Train the model using the training data
svm_model.fit(X_train, y_train)
```
**Step 4: Making Predictions**
```python
# Make predictions on the test data
y_pred = svm_model.predict(X_test)
# Evaluate the performance of the model using accuracy score
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
```
Key Performance Metrics for Evaluating SVMs
When evaluating the performance of an SVM classifier, there are several key metrics to keep in mind:
* **Accuracy**: The proportion of correctly classified instances out of the total number of instances.
* **Precision**: The proportion of true positives out of the total number of positive predictions.
* **Recall**: The proportion of true positives out of the total number of actual positive instances.
* **F1-Score**: The harmonic mean of precision and recall.
Real-World Applications of SVMs
Support Vector Machines have been applied in a wide range of domains, including:
* **Image classification**: SVMs have been used in image classification tasks, such as handwritten digit recognition, object recognition, and image retrieval.
* **Text classification**: SVMs have been used in text classification tasks, such as sentiment analysis, spam detection, and topic modeling.
* **Bioinformatics**: SVMs have been used in bioinformatics applications, such as predicting protein subcellular localization, identifying gene expression, and predicting disease risk.
Conclusion
Support Vector Machines are a powerful tool in the field of Machine Learning, offering a robust and generalizable approach to classification and regression tasks. By understanding the key components of SVMs, including the kernel, hyperplane, support vectors, and margin, developers can unlock the full potential of these algorithms and apply them to a wide range of real-world applications. Whether you're a seasoned developer or just starting your journey in Machine Learning, this article has provided a comprehensive guide to SVMs and their practical implementation.

Related Post

Lecy Goranson Marriage: A Deep Dive Into Her Personal Life

The Future of Finance: How Money6X Com is Revolutionizing the Industry

Unveiling the Enigmatic Eorme: Unlocking the Secrets of This Ancient, Forgotten Civilization

The Hidden Life of David Freiburger's Wife: Unveiling the Mystery Behind the Magician's Partner



